The OPTX Service Assurance Platform
In OPTX, full-stack monitoring capabilities are coupled with a range of innovative features to deliver a unified, intelligent and business-aligned view of your IT services and infrastructure.
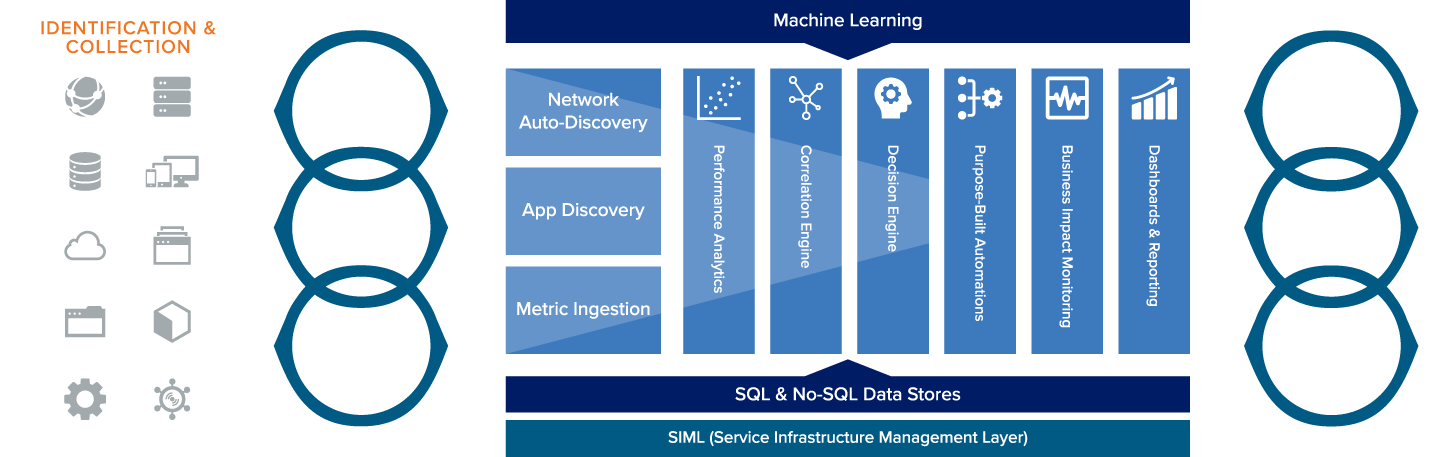
Architectural Insights
OPTX features a number of patented technology innovations that enable you to detect, diagnose and resolve service issues more quickly and accurately – increasing IT service quality and driving down operational costs.






Success comes in many forms
A GLOBAL ENTERPRISE SERVICES ORGANIZATION